Definición de Cliente Servidor
Entre las principales definiciones
se tiene:
Desde un punto de vista conceptual:
«Es un modelo para construir
sistemas de información, que se sustenta en la idea de repartir el tratamiento
de la información y los datos por todo el sistema informático, permitiendo
mejorar el rendimiento del sistema global de información»
En términos de arquitectura:
Los distintos aspectos que caracterizan a una
aplicación (proceso, almacenamiento, control y operaciones de entrada y salida de
datos) en el sentido más amplio, están situados en más de un computador, los
cuales se encuentran interconectados mediante una red de comunicaciones».
3.
Cliente/Servidor
«Es la
tecnología que proporciona al usuario final el acceso transparente a las aplicaciones,
datos, servicios de cómputo o cualquier otro recurso del grupo de trabajo y/o,
a través de la organización, en múltiples plataformas. El modelo soporta un
medio ambiente distribuido en el cual los requerimientos de servicio hechos
por estaciones de trabajo inteligentes o "clientes'', resultan en un
trabajo realizado por otros computadores llamados servidores".
¿Que es un Cliente?
Es el que inicia un requerimiento
de servicio. El requerimiento inicial puede convertirse en múltiples
requerimientos de trabajo a través de redes LAN o WAN. La ubicación de los
datos o de las aplicaciones es totalmente transparente para el cliente.
¿Que es un Servidor?
Es cualquier recurso de cómputo
dedicado a responder a los requerimientos del cliente. Los servidores
pueden estar conectados a los clientes a través de redes LANs o WANs,
para proveer de múltiples servicios a los clientes y ciudadanos tales como
impresión, acceso a bases de datos, fax, procesamiento de imágenes, etc.
¿Que es una Arquitectura?
Una arquitectura es un entramado de
componentes funcionales que aprovechando diferentes estándares, convenciones,
reglas y procesos, permite integrar una amplia gama de productos y servicios
informáticos, de manera que pueden ser utilizados eficazmente dentro de la
organización.
Debemos
señalar que para seleccionar el modelo de una arquitectura, hay que partir del
contexto tecnológico y organizativo del momento y, que la arquitectura
Cliente/Servidor requiere una determinada especialización de cada uno de los
diferentes componentes que la integran.

Evolución del modelo Cliente Servidor
·
Mono-capa
·
Data Base Server – Computación centralizada
·
Two-Tier – Proceso de transacciones
·
Multi-tier
Client/Server
·
Three-tier
·
Multi-tier
·
N-tier
Aplicaciones mono-capa
Entendemos por
aplicaciones mono-capa, aquellas que tanto la propia aplicación como los datos
que maneja se encuentran en la misma máquina y son administradas por la misma
herramienta: podríamos decir que son una sola entidad

Figura
1. Arquitectura Típica de una aplicación de una sola capa.
Modelo En Dos Capas (Two-Tier Model)
En una arquitectura cliente/servidor clásica tenemos dos "capas"
(two-tier):
o
Una donde está el cliente que implementa la interface.
- Otra donde se encuentra el gestor de bases de datos que trata las peticiones recibidas desde el cliente.
La lógica de la aplicación se encuentra por tanto repartida entre el cliente
y servidor.
Un ejemplo de esta configuración podría ser un applet Java que
se carga en el navegador del cliente y trabaja directamente con la base de
datos mediante JDBC.

Figura A: Esquema de arquitectura Cliente/Servidor
clásica.
|
Ventajas de este
modelo:
o
Se mantiene una conexión persistente con la base de
datos.
- Se minimizan las peticiones en el servidor trasladándose la mayor parte del trabajo al cliente.
- Se gana en rendimiento gracias a la conexión directa y permanente con la base de datos. A través de una única conexión se realiza el envío y recepción de varios datos.
Inconvenientes:
o
La más importante desventaja, es que esta solución es
muy dependiente del tipo controlador JDBC que se utilice para acceder a la base
de datos. El acceso se realiza desde el cliente y esto significa que es él el
que tiene que tener instalado en su sistema los controladores necesarios para
que se produzca la comunicación con la base de datos.
- Además hay que tener en cuenta que el modelo de seguridad de Java impide que desde un applet sin validar (lo que se conoce como untrusted applet), como lo son la mayoría de los que se ejecutan en un navegador, se puedan realizar las siguientes operaciones:
- El acceso general, y por supesto mediante JDBC, a bases de datos situadas en direcciones URL distintas a las que procede el mismo applet.
- La configuración de recursos locales como, por ejemplo, la información de la fuente de datos ODBC para usar el puente JDBC-ODBC.
- La descarga de clases nativas, es decir, aquellas cuyo nombre empieza por Java. Esta restricción afecta directamente a los navegadores que utilizan JDK 1.0.2 o anterior, pues JDBC es posterior a esta versión, de forma que las clases apropiadas no estarán instaladas localmente ni podrán ser descargadas de Internet por el applet.
- Finalmente debemos tener en cuenta que es bien conocido que los programas Java pueden ser descompilados muy fácilmente con lo que introducir el acceso a nuestras bases de datos mediante un applet Java conlleva un riesgo considerable en cuanto a la seguridad.
Modelo en Tres Capas (Three-Tier Model)
Con la arquitectura cliente/servidor en tres capas (three-tier)
añadimos una nueva capa entre el cliente y el servidor donde se implementa la
lógica de la aplicación. De esta forma el cliente es básicamente una interface,
que no tiene por qué cambiar si cambian las especificaciones de la base de
datos o de la aplicación; queda aislado completamente del acceso a los datos.
Así un applet de Java se carga en el navegador del cliente y se comunica con
un servlet que corre en la máquina servidor; o bien accedemos a la base de
datos a través de un formulario HTML. El servlet establece una conexión a la
base de datos mediante JDBC.
En este caso se tiene total libertad
para escoger dónde se coloca la lógica de la aplicación: en el cliente, en el
servidor de base de datos, o en otro(s) servidor(es). También se tiene total
libertad para la elección del lenguaje a utilizar.
Se utiliza un lenguaje de tipo
general (probablemente C) por lo que no existen restricciones de funcionalidad.
Los programas serán óptimos desde el
punto de vista de la performance.
También deberá implementarse
especialmente el Call remoto, lo que seguramente se hará de una forma más libre
que los Remote Procedure Call actualmente disponibles.
No existe compromiso alguno con el
uso de lenguajes propietarios, por lo que las aplicaciones serán totalmente
portables sin cambio alguno.
Puede determinarse en qué
servidor(es) se quiere hacer funcionar estos procedimientos. En aplicaciones
críticas se pueden agregar tantos servidores de aplicación como sean
necesarios, de forma simple, y sin comprometer en absoluto la integridad de la
base de datos, obteniéndose una escalabilidad muy grande sin necesidad de tocar
el servidor de dicha base de datos.
El problema de esta arquitectura es
¿cómo se implementa?. Parece ilusorio tratar de programar manualmente estos
procedimientos, mientras que, si se dispone de una herramienta que lo hace
automáticamente, presenta ventajas claras sobre la alternativa anterior:

Figura B: Arquitectura Cliente/Servidor en tres
capas (three-tier)
|
Como se podría esperar
cada uno de los componentes de la aplicación en una arquitectura three-tier se
separa en una sola entidad. Esto te permite implementar componentes de una
manera más flexible. Algo que no creo que sorprenda es la afirmación de que
este tipo de arquitectura es la más compleja.
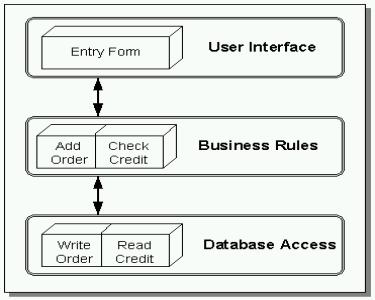
Figura 4. Arquitectura Three-Tier.
En esta Arquitectura
todas las peticiones de los clientes se controlan en la capa correspondiente a
la lógica del negocio. Cuando el cliente necesita hacer una petición se la hace
a la capa en la que se encuentra la lógica del negocio. Esto es bastante
importante pues eso quiere decir que:
- 1.- El cliente no tiene que tener drivers ODBCni la problemática consiguiente de instalación de los drivers por tanto se reduce el costo de mantener las aplicaciones cliente
- 2.- El Cliente y el Gestor de Reglas de negocio tienen que hablar el mismo lenguaje (en nuestro caso COM)
- 3.- El Gestor de Reglas de Negocio y el Servidor de Datos tienen que hablar el mismo lenguaje (en nuestro caso ODBC)
Lo ideal sería que el
Gestor de Reglas de Negocio no sólo OLE y ODBC sino otros estandares como
DBLib, OLI, DRDA, SQL/API y X/Open
Ventajas de este modelo:
o
No existe ningún problema con respecto al tipo de
controlador JDBC utilizado para acceder a la base de datos.Todos los recursos
necesarios para establecer la conexión con la base de datos se encuentran en el
servidor y por tanto, el cliente no necesita instalar nada adicional en su
máquina para poder acceder a la base de datos.
- Esta arquitectura proporciona considerables mejoras desde el punto de vista de la portabilidad de la aplicación, escalabilidad, robustez y reutilización del código. Asimismo facilita las tareas de migración o cambios en el sistema gestor de la base de datos.
- Desaparecen las restricciones debidas a las limitaciones de los applets impuestas por el modelo de seguridad de Java.
o
Esta solución es algo menos eficiente que la del modelo
de dos capas, ya que hemos añadido una capa intermedia más de software.
Arquitectura de N Tier
Windows DNA distribuye una aplicación
entre varias capas llamadas niveles. Aunque los niveles algunas veces residen
físicamente en máquinas diferentes, Windows® DNA enfatiza la distribución
lógica. Mientras que los nombres de estos niveles difieren de acuerdo a la
fuente, la Guía del Desarrollador de BackOffice® (BackOffice® Developer's
Guide, BDG) se refiere a ellos como sigue:
- Servicios de usuario.
- Servicios de negocios.
- Servicios de datos.

Este diagrama muestra como varias
aplicaciones y tecnologías de Microsoft son implementadas en la arquitectura N
niveles. Al leer la BDG, Usted verá como estos niveles trabajan juntos para
proporcionar la funcionalidad, estabilidad y escalabilidad que las aplicaciones
empresariales requieren. Como lo indica el diagrama, Windows DNA sintetiza en
las aplicaciones un conjunto común de servicios, incluyendo HTML y HTML
dinámico (DHTML), controles ActiveX®, componentes del Modelo de Objeto
Componente (COM), scripts en el lado cliente y en el lado servidor,
transacciones, seguridad y servicios de directorio, acceso a datos y a bases de
datos, administración de sistemas y ambientes de creación de componentes. Estos
servicios son expuestos de manera unificada a través del COM, el cual permite
que las aplicaciones interoperen y compartan componentes.
Las principales ventajas del
desarrollo en N niveles son respecto a la escalabilidad. Las aplicaciones que
procesan su lógica de negocios, ya sea en las máquinas cliente o en las bases
de datos, se vuelven lentas cuando están siendo muy utilizadas. Esto se ha
convertido en algo muy importante en esta era donde las aplicaciones de Web
pueden ser utilizadas millones de veces por día. La transición para el
desarrollo N niveles no es gratis, el tiempo de desarrollo se incrementó debido
a la complejidad de añadir otro nivel. Afortunadamente, el middleware, tal como
el MTS, fue desarrollado para manejar automáticamente los detalles de la infraestructura
de aplicación, tal como el manejo de procesos alternos y los detalles de COM.
WEBGRAFIA
http://docente.ucol.mx/sadanary/public_html/bd/cs.htm
WEBGRAFIA
http://docente.ucol.mx/sadanary/public_html/bd/cs.htm
21 de Julio del 2012
Gracias :3
ResponderEliminar